搜索到
195
篇与
后端
的结果
-

-
-
Redis离线安装与在线安装 离线安装Redis官网下载Redis压缩包下载地址:http://redis.io/download,下载最新文档版本。 通过WinSCP等远程管理工具,将压缩包复制到Linux服务器这里在Linux中创建目录:/redis,并将压缩包复制到该目录: $ mkdir /redis 解压压缩文件,并执行make对解压后的文件进行编译在Linux中通过命令方式下载并安装: $ cd /redis# 将redis解压到/dml/redis目录$ tar -zxvf redis-4.0.11.tar.gz$ cd redis-4.0.11# 编译$ make 解压:查看解压后的目录:进入解压目录查看:编译:编译时出现gcc错误:安装gcc依赖: $ yum install gcc 再次编译安装: $ make MALLOC=libc 编译完后,可以看到解压文件redis中会对应的src、conf等文件夹。直接启动Redis进入src文件夹,查看目录,找到redis-server服务:直接启动Redis服务: $ ./redis-server 出现如下界面表示已启动 redis服务:在线安装Redis在CentOS系统在线安装 Redis 可以使用以下命令获得最近的软件包的列表: $ sudo yum update 安装Redis服务端: $ sudo yum install redis-server 启动 Redis服务: $ ./redis-server 以后台进程方式启动Redis第一步:修改redis.conf文件 $ vim redis.conf 将:daemoize no改为daemoize yes,保存并退出。文档中:databases 16表示Redis中默认的数据库有16个,但没有名字。 第二步:在src下 指定redis.conf文件启动 $ ./redis-server /redis/redis-4.0.11/redis.conf redis.conf是一个默认的配置文件。我们可以根据需要使用自己的配置文件。 启动Redis客户端在成功启动Redis服务后,即可启动客启端。注意:这里最好再开一个终端测试。进入Redis-4.0.11/src目录,启动Redis客户端: $ ./redis-cli 以上命令将打开以下终端: 127.0.0.1:6379> 127.0.0.1 是本机 IP ,6379 是Redis服务端口。现在我们输入PING命令,测试是否连接成功。 127.0.0.1:6379> ping 如果现面 PONG 表示连接成功。 关闭Redis第一步:查看redis进程 $ ps -aux | grep redis 第二步:杀死进程 $ kill -9 1693
-
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: connect ti redis连接报错:redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: connect timed out开启防火墙(systemctl start firewalld)1.使用命令 firewall-cmd --state查看防火墙状态。得到结果是running或者not running2.在running 状态下,向firewall 添加需要开放的端口命令为 firewall-cmd --permanent --zone=public --add-port=6379/tcp //永久的添加该端口。去掉--permanent则表示临时。4.firewall-cmd --reload //加载配置,使得修改有效。5.使用命令 firewall-cmd --permanent --zone=public --list-ports //查看开启的端口,出现6379/tcp这开启正确 在redis客户端输入:config set protected-mode "no"再测试:@Test public void test(){ Jedis jedis = new Jedis("192.168.***.***" , 6379); jedis.set("key2", "aaaaaa"); String key2 = jedis.get("key2"); System.out.println("获取到的key2为:"+key2); jedis.close(); }
-
redis配置 分布式锁及string、list、hash、set、zset基本操作 配置:spring: redis: host: 127.0.0.1 port: 6379 password: jedis: pool: max-wait: -1ms #最大建立连接等待时间。如果超过此时间将接到异常。设为-1表示无限制。 max-idle: 100 #最大等待连接中的数量,设 0 为没有限制 max-active: 300 #最大连接数据库连接数,设 0 为没有限制 min-idle: 10 #最小等待连接数<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>操作:package com.demo.util; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisCallback; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.ZSetOperations; import org.springframework.stereotype.Component; import java.util.List; import java.util.Map; import java.util.Objects; import java.util.Set; import java.util.concurrent.TimeUnit; @Component public class RedisUtil { @Autowired private StringRedisTemplate stringRedisTemplate; @Autowired private RedisTemplate redisTemplate; //解锁时间 public static final int LOCK_EXPIRE = 1000; // ms /** * 读取缓存 * * @param key * @return */ public Object get(final String key) { return redisTemplate.opsForValue().get(key); } /** * 写入缓存 */ public boolean set(final String key, Object value) { boolean result = false; try { redisTemplate.opsForValue().set(key, value); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 写入缓存 自定义有效时间 * TimeUnit是java.util.concurrent包下面的一个类,表示给定单元粒度的时间段 * 主要作用 * 时间颗粒度转换 * 延时 * * TimeUnit.DAYS //天 * TimeUnit.HOURS //小时 * TimeUnit.MINUTES //分钟 * TimeUnit.SECONDS //秒 * TimeUnit.MILLISECONDS //毫秒 */ public boolean set(final String key, Object value,Long timeout) { boolean result = false; try { redisTemplate.opsForValue().set(key, value,timeout, TimeUnit.SECONDS); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 更新缓存 */ public boolean getAndSet(final String key, Object value) { boolean result = false; try { redisTemplate.opsForValue().getAndSet(key, value); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 删除缓存 */ public boolean delete(final String key) { boolean result = false; try { redisTemplate.delete(key); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 分布式锁 * * @param key key值 * @param lockPrefix 锁的前缀 * @return 是否获取到 */ public boolean lock(String key,String lockPrefix){ String lock = lockPrefix + key; // lambda表达式 return (Boolean) redisTemplate.execute((RedisCallback) connection -> { long expireAt = System.currentTimeMillis() + LOCK_EXPIRE + 1; Boolean acquire = connection.setNX(lock.getBytes(), String.valueOf(expireAt).getBytes()); if (acquire) { return true; } else { byte[] value = connection.get(lock.getBytes()); if (Objects.nonNull(value) && value.length > 0) { long expireTime = Long.parseLong(new String(value)); if (expireTime < System.currentTimeMillis()) { // 如果锁已经过期 byte[] oldValue = connection.getSet(lock.getBytes(), String.valueOf(System.currentTimeMillis() + LOCK_EXPIRE + 1).getBytes()); // 防止死锁 return Long.parseLong(new String(oldValue)) < System.currentTimeMillis(); } } } return false; }); } /** * 解锁 * * @param key */ public void unlock(String key,String lockPrefix) { redisTemplate.delete(lockPrefix+key); } /** * 例子 * boolean lock = lock("123", "LOCK"); if (lock) { unlock("123", "LOCK"); } else { // 设置失败次数计数器, 当到达5次时, 返回失败 int failCount = 1; while (failCount <= 5) { // 等待100ms重试 try { Thread.sleep(100L); } catch (InterruptedException e) { e.printStackTrace(); } if (lock("123", "LOCK")) { unlock("123", "LOCK"); } else { failCount++; } } }*/ //STRING---------------- /** * String * @param key * @param value * @param expirationTime */ public void setString(String key, String value,long expirationTime) { //SECONDS 秒 MINUTES 分钟 HOURS 小时 this.stringRedisTemplate.opsForValue().set(key, value,expirationTime, TimeUnit.SECONDS); } /** * * @param key * @return String */ public String getStringByKey(String key) { return this.stringRedisTemplate.opsForValue().get(key); } /** * * @param key */ public Boolean deleteStringByKey(String key) { return this.stringRedisTemplate.delete(key); } // LIST ------------------------------------- /** * 示例: * 起始数据: 1 2 3 * 添加: 4 * 结果: 4 1 2 3 * @param key * @param value */ public Long setListLeft(String key,String value){ return this.stringRedisTemplate.opsForList().leftPush(key, value); } /** * 示例: * 起始数据: 1 2 3 * 添加: 4 * 结果: 1 2 3 4 * @param key * @param value */ public Long setListRight(String key,String value){ return this.stringRedisTemplate.opsForList().rightPush(key,value); } /** * * @param key * @param i 起始下标(包含) * @param n 结束下标 (包含) (查询全部结束下标为-1) * @return */ public List<String> getList(String key,int i,int n){ return stringRedisTemplate.opsForList().range( key, i, n); } /** * 示例: * 删除先进入的B元素(如果含有多个B元素,删除最左边的) * stringRedisTemplate.opsForList().remove("redlist",1, "B");//["0","1","2","A"] * 删除所有A元素 * stringRedisTemplate.opsForList().remove("redlist",0, "A");//["0","1","2"] * @param key * @param i * @param str * @return */ public Long deleteByListKey(String key,int i,String str){ return stringRedisTemplate.opsForList().remove(key, i, str); } //HASH -------------------------------- /** * * @param rKey redis键 * @param mKey map键 * @param mValue map值 */ public void setHash(String rKey,String mKey,String mValue){ stringRedisTemplate.opsForHash().put(rKey,mKey,mValue); } /** * 获取map对象 * 示例:{"a":"d","b":"d"} * @param rKey redis键 * @return */ public Map<Object, Object> getHashMap(String rKey){ return stringRedisTemplate.opsForHash().entries(rKey); } /** * 获取map的key * 示例:["a","b"] * @param rKey redis键 * @return */ public Set<Object> getHashMapKey(String rKey){ return stringRedisTemplate.opsForHash().keys(rKey); } /** * 获取map的key * 示例:["d","d"] * @param rKey redis键 * @return */ public List<Object> getHashMapValue(String rKey){ return stringRedisTemplate.opsForHash().values(rKey); } /** * 获取map大小 * @param rKey redis键 * @return */ public long getHashMapSize(String rKey){ return stringRedisTemplate.opsForHash().size(rKey); } /** * * @param rKey redis键 * @param mKey map键一个或多个(当删除完所有的key时,该map对象注销) */ public Long deleteHashMapByKey(String rKey,String... mKey ){ return stringRedisTemplate.opsForHash().delete(rKey, mKey); } //SET ================== /** * * @param key redis键 * @param value 一个或多个 * @return */ public Long setSet(String key ,String... value){ return stringRedisTemplate.opsForSet().add(key,value); } /** * * @param key redis键 * @return */ public Set<String> getSet(String key){ return stringRedisTemplate.opsForSet().members(key); } /** * 判断值是否存在set集合中 * @param key redis键 * @param value set集合里的值 * @return */ public Boolean isMember(String key,String value){ return stringRedisTemplate.opsForSet().isMember(key,value); } /** * * @param key redis键 * @param value set集合里的值(当值都清空时,key注销) * @return */ public Long deleteSet(String key,String... value){ return stringRedisTemplate.opsForSet().remove(key,value); } //ZSET================================ /** * 向指定集合zset中添加元素value,score用于排序,如果该元素已经存在,则更新其顺序 * @param key * @param value * @param d * @return */ public Boolean setZSet(String key,String value,Double d){ return stringRedisTemplate.opsForZSet().add(key, value, d); } /** * value在集合中时,返回其score;如果不在,则返回null * @param key * @param value * @return */ public Double getScore(String key, String value) { return stringRedisTemplate.opsForZSet().score(key, value); } /** * 查询集合中指定顺序的值, 0 -1 表示获取全部的集合内容 zrange * * 返回有序的集合,score小的在前面 * * @param key * @param start * @param end * @return */ public Set<String> range(String key, int start, int end) { return stringRedisTemplate.opsForZSet().range(key, start, end); } /** * 查询集合中指定顺序的值和score,0, -1 表示获取全部的集合内容 * * @param key * @param start * @param end * @return */ public Set<ZSetOperations.TypedTuple<String>> rangeWithScore(String key, int start, int end) { return stringRedisTemplate.opsForZSet().rangeWithScores(key, start, end); } /** * 查询集合中指定顺序的值 zrevrange * * 返回有序的集合中,score大的在前面 * * @param key * @param start * @param end * @return */ public Set<String> revRange(String key, int start, int end) { return stringRedisTemplate.opsForZSet().reverseRange(key, start, end); } /** * 根据score的值,来获取满足条件的集合 zrangebyscore * * @param key * @param min * @param max * @return */ public Set<String> sortRange(String key, int min, int max) { return stringRedisTemplate.opsForZSet().rangeByScore(key, min, max); } /** * zset中的元素塞入之后,可以修改其score的值, * 当元素不存在时,则会新插入一个 * @param key * @param value * @param score * @return */ public Double incrScore(String key, String value, double score) { return stringRedisTemplate.opsForZSet().incrementScore(key, value, score); } /** * 判断value在zset中的排名 * * @param key * @param value * @return */ public Long rank(String key, String value) { return stringRedisTemplate.opsForZSet().rank(key, value); } /** * 返回集合的长度 * * @param key * @return */ public Long size(String key) { return stringRedisTemplate.opsForZSet().zCard(key); } } package com.demo.dto; import java.io.Serializable; /** * @Author: LiuYong * @Date:2020/04/26 9:57 * @Description: TODO 描述 */ public class UserDto implements Serializable { private static final long serialVersionUID = -5255173691529786212L; private String userId; private String userName; public String getUserId() { return userId; } public void setUserId(String userId) { this.userId = userId; } public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } @Override public String toString() { return "UserDto{" + "userId=" + userId + ", userName='" + userName + '\'' + '}'; } } package com.demo; import com.demo.dto.UserDto; import com.demo.util.RedisUtil; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class DemoApplicationTests { @Autowired private RedisUtil redisUtil; @Test void contextLoads() { UserDto userDto = new UserDto(); userDto.setUserName("张三"); userDto.setUserId("1"); boolean user = redisUtil.set("user", userDto); System.out.println(user); UserDto user1 = (UserDto)redisUtil.get("user"); System.out.println(user1); } } 附:redis Windows工具https://www.electronjs.org/apps/anotherredisdesktopmanager
-
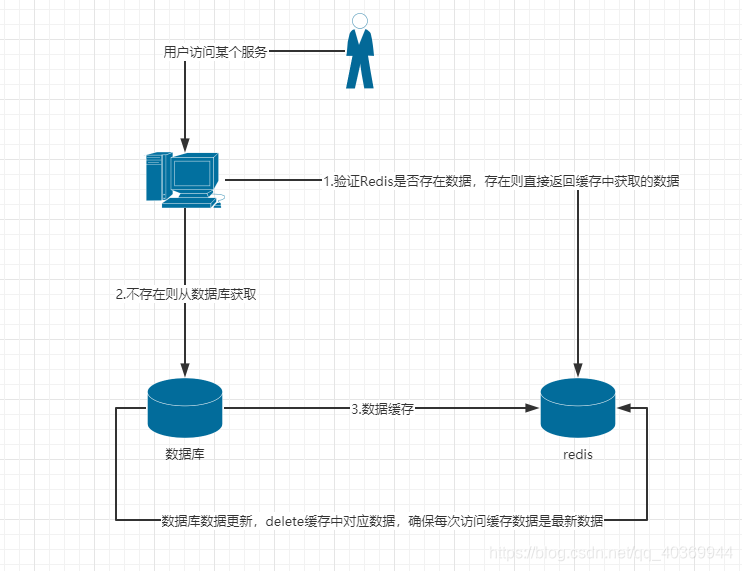
Redis 介绍及各类策略、问题解决 目录 一、Redis介绍 1.1数据类型 1.2优缺点 二、为什么要使用Redis/缓存?2.1高性能 2.2高并发三、持久化3.1什么是持久化?3.2持久化机制3.2.1Redis DataBase(简称RDB) 3.2.3Append-only file (简称AOF)四、Redis过期键的删除策略4.1常见删除策略五、Redis内存淘汰策略5.1全局的键空间选择性移除5.2设置过期时间的键空间选择性移除六、缓存异常6.1缓存雪崩6.2缓存穿透6.3缓存击穿一、Redis介绍简单来说Redis是一款高性能非关系型的键值对数据库。与传统数据库不同的是Redis的数据是存储在内存中,所以读写速度非常快。因此被广泛应用于缓存方面,每秒可处理超过10W次的读写操作,Redis也经常用来做分布式锁,此外,Redis支持事务、持久化、LUA脚本、LRU驱动事件、多集群方案。Redis可以存储键和五种不同类型的值之间的映射,键类型只能为字符串,支持五种数据类型:String、List、Set、ZSet、Hash。 1.1数据类型数据类型可以存储的值操作应用场景STRING字符串、整数或者浮点数对整个字符串或者字符串的其中一部分执行操作对整数和浮点数执行自增或者自减操作做简单的键值对缓存LIST列表从两端压入或者弹出元素对单个或者多个元素进行修剪,只保留一个范围内的元素存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的数据SET无序集合添加、获取、移除单个元素检查一个元素是否存在于集合中计算交集、并集、差集从集合里面随机获取元素交集、并集、差集的操作,比如交集,可以把两个人的粉丝列表整一个交集HASH包含键值对的无序散列表添加、获取、移除单个键值对获取所有键值对检查某个键是否存在结构化的数据,比如一个对象ZSET有序集合添加、获取、删除元素根据分值范围或者成员来获取元素计算一个键的排名去重但可以排序,如获取排名前几名的用户 1.2优缺点优:读写速度快支持数据持久化,AOF和RDB两种方式支持事务数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构支持主从复制,主机会自动将数据同步到从机,可以进行读写分离缺:数据库受物理内存限制,不适合海量数据高性能读写,一般作用于小数据量的高性能操作和运算Redis不具备自动容错和恢复功能,主从机的宕机都有可能造成读写失败,需等待重启或前端手动更改IP才能恢复主机宕机前有部分数据未能同步到从机,切换IP后有可能造成数据不一致的问题,降低了系统可用性能Redis较难支持在线扩容,在集群容量达到上限后在线扩容会变得复杂,运维人员得在运行前确保有足够的容量 二、为什么要使用Redis/缓存? 2.1高性能如用户第一次获取数据时是从数据库获取,因数据是从硬盘上读取,相对缓慢一些。将此次请求数据存于缓存,再次访问数据时是从缓存中获取,是直接操作内存,速度相对会快很多。如果数据库中数据发生变化,则把相应Key缓存数据删除,下次获取数据又会和第一次获取数据一样,且确保数据是最新数据。 2.2高并发直接操作缓存请求远远大于直接请求数据库,以秒杀/抢红包为例,在活动开始前把数据存储在缓存中,活动结束后再同步redis数据到数据库。三、持久化 3.1什么是持久化?持久化就是将数据存储到磁盘,以防宕机数据丢失无法恢复。 3.2持久化机制 3.2.1Redis DataBase(简称RDB)执行机制:快照,直接将databases中的key-value的二进制形式存储在了rdb文件中优点:性能较高(因为是快照,且执行频率比aof低,而且rdb文件中直接存储的是key-values的二进制形式,对于恢复数据也快)使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能缺点:在save配置条件之间若发生宕机,此间的数据会丢失RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候 3.2.3Append-only file (简称AOF)执行机制:将对数据的每一条修改命令追加到aof文件优点:数据不容易丢失可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)缺点:性能较低(每一条修改操作都要追加到aof文件,执行频率较RDB要高,而且aof文件中存储的是命令,对于恢复数据来讲需要逐行执行命令,所以恢复慢)AOF文件比RDB文件大,且恢复速度慢。 四、Redis过期键的删除策略 4.1常见删除策略定时删除:每个设置过期时间的Key都会创建一个定时器,到期就会定时删除,该策略会立即删除过期数据,对内存很友好。但是相对的会占用大量的CPU资源去处理过期数据处理,从而会影响缓存响应时间及吞吐量。惰性删除:对CPU来说是最友好,只会在程序读取该数据时校验数据是否存在,不存在就删除。但是相对的对内存来说不友好,比如一些已经过去的数据,不去读取时永远不知道是否过期,更不会删除,这个键就一直存在,占用着内存资源。定期删除:就是前两种策略的整合和折中,每隔一段时间程序执行一次过期键删除操作,通过限制删除的频率和时长来减少删除操作对CPU的影响。有效的减少了过期键对内存资源的占用 五、Redis内存淘汰策略Redis内存淘汰策略是指在内存不足时,新数据怎么申请额外的空间数据。 5.1全局的键空间选择性移除noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。 5.2设置过期时间的键空间选择性移除volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。 Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。 六、缓存异常 6.1缓存雪崩缓存雪崩是指缓存数据同一时间大面积过期,造成所有请求都访问数据库,因短时间请求压力过大从而造成数据库崩掉。解决方案:随机设置过期时间,避免同一时间过期并发量不是特别多的,最多处理方式是加锁排队给每个缓存数据添加标记,记录缓存是否失效,如果失效则更新缓存6.2缓存穿透缓存穿透是指数据库和缓存中都没有数据,造成所有请求都访问数据库,因短时间请求压力过大从而造成数据库崩掉。解决方案:接口增加校验,如用户ID<0的直接拦截从缓存获取不到数据,数据库也不存在该数据,则设置一个Key-Value,Value=null的缓存,缓存时间可以设置30S,这样可以防止重复用一个ID暴力攻击。采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力6.3缓存击穿缓存击穿是指没有获取到缓存数据(一般是缓存过期),由于并发用户量大,同时获取一条数据,没从缓存中获取的,请求全到数据库上,造成数据库压力过大。和缓存雪崩不同的是,缓存击穿是并发查询同一条数据,而缓存雪崩是大片数据过期,很多数据查不到都查询数据库。解决方案:热点数据永不过期添加互斥锁,对缓存查询加锁,如果KEY不存在,就加锁,然后查数据库入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入数据库查询
-
-
-
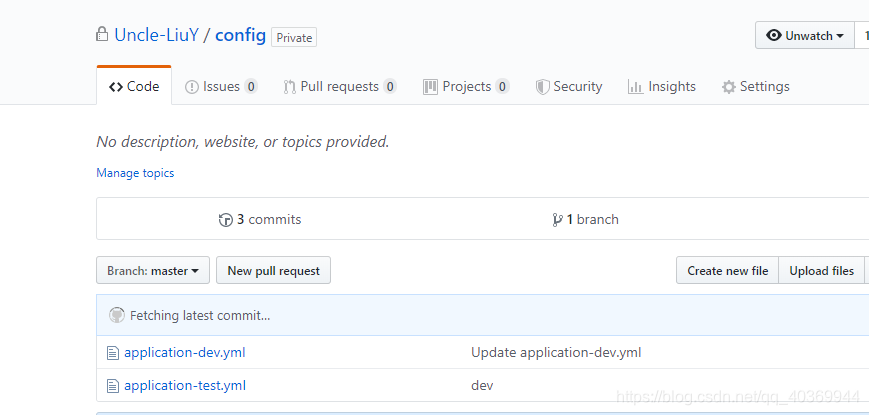
Spring Cloud 入门 之 Config(六)附源码 一、前言本文是根据笔者上篇文章项目进行修改,若有不懂,请转《Spring Cloud 入门 之 Zuul(五)附源码》二、介绍Spring Cloud Config为分布式系统中的外部化配置提供服务器和客户端支持。使用Config Server,您可以在所有环境中管理应用程序的外部属性。特征:Spring Cloud Config Server功能:用于外部配置的HTTP,基于资源的API(名称 - 值对或等效的YAML内容)加密和解密属性值(对称或非对称)使用可轻松嵌入Spring Boot应用程序 @EnableConfigServerConfig Client功能(适用于Spring应用程序):绑定到Config Server并Environment使用远程属性源初始化Spring加密和解密属性值(对称或非对称)三、实战演练服务实例端口描述eureka-server9000注册中心(Eureka 服务端)config-server10000配置中心(Eureka 客户端、Config 服务端)api80服务接口(Eureka 客户端、Config 客户端)3.1上传配置在 GitHub 上新建一个私有仓库,名为config创建application-dev.yml和application-test.yml,这是之前api中application.yml的参数。两者之间只有env 的值不同,其中一个是 dev ,另一个是 test。provider: # 名称 name: provider # 版本 version: 1.0 # 版权年份 copyrightYear: 2019 # 文件上传路径 profile: profile/ # 获取ip地址开关 addressEnabled: trueenv: dev1 server: port: 80spring: application: name: api eureka: client:# register-with-eureka: false # 不向注册中心注册自己 fetch-registry: true # 是否检索服务 service-url: defaultZone: http://localhost:9000/eureka/ # 注册中心访问地址feign: hystrix: enabled: true #开启服务降级功能 client: config: default: connect-timeout: 10000 read-timeout: 20000 service-test: connect-timeout: 10000 read-timeout: 20000management: endpoints: web: exposure: include: "*"3.2 创建config 服务端新建一个 spring boot 项目,名为 config-server3.2.1 添加依赖 <!-- eureka 客户端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> <version>2.1.0.RELEASE</version> </dependency> <!-- config 服务端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> <version>2.1.0.RELEASE</version> </dependency>3.2.2 application.ymlserver: port: 10000spring: application: name: CONFIG cloud: config: server: git: uri: https://github.com/Uncle-LiuY/config.git username: ****** password: ****** eureka: instance: instance-id: config-api client: service-url: defaultZone: http://localhost:9000/eureka/ 服务注册中心ַ3.2.3 修改启动类@EnableConfigServer @EnableEurekaClient3.2.4 启动测试依次启动eureka-server、config-server在浏览器访问 http://localhost:10000/application-dev.yml 和 http://localhost:10000/application-test.yml其中,访问规则如下:<IP:PORT>/{name}-{profiles}.yml <IP:PORT>/{label}/{name}-{profiles}.yml name:文件名,可当作服务名称profiles: 环境,如:dev,test,prolable: 分支,指定访问某分支下的配置文件,默认拉去 master 分支。 3.3 config 客户端对api进行修改3.3.1 添加配置: <!-- config 客户端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-client</artifactId> <version>2.1.0.RELEASE</version> </dependency>3.3.2 删除 application.yml,并新建 bootstrap.yml,保存如下内容:spring: application: name: api cloud: config: discovery: enabled: true service-id: CONFIG # config-server 在注册中心的名称 profile: dev # 指定配置文件的环境 eureka: client: service-url: defaultZone: http://localhost:9000/eureka/ # 注册中心访问地配置中,通过 spring.cloud.config.discovery.service-id 确定配置中心,再通过 spring.application.name 的值拼接 spring.cloud.config.profile 的值,从而确定需要拉去从配置中心获取的配置文件。(如:application-dev)注意:必须保留 eureka 注册中心的配置,否则 API 无法连接注册中心,也就无法获取配置中心(config-server)的访问信息。3.3.4 测试类@RestController@RequestMapping("/test")public class TestController { @Value("${env}") private String env; // 从配置中心获取 @RequestMapping("/getConfigInfo") public String getConfigInfo() { return env; } }打开浏览器访问 http://localhost/test/getConfigInfo,结果如下图:根据配置文件中的端口进行访问,这里配置的是80端口成功获取 config-server 从远程私有仓库拉去的数据,由于在 bootstrap.yml 中配置了 spring.cloud.config.profile=dev,因此拉取到的数据就是 application-dev.yml 中的数据。在GitHub上修改配置文件的参数,依次启动config-server、api4.项目源码下载当我们修改远程私有仓库的配置文件时,Config Server 如何知道是否该重新获取远程仓库数据呢?现在已知唯一的解决方式就是重启 Config Client 项目,在项目启动时会请求 Config Server 重新拉去远程私有仓库数据。但是,如果是在生产环境下随便重启项目必定会影响系统的正常运行,那有没有更好的方式解决上述的问题呢?详情请查看《Spring Cloud 整合 Bus(附源码)》
-
Spring Cloud入门之Eureka(一) 目录1.前言2.介绍3.搭建注册中心3.1 创建Spring Boot项目3.2导入依赖3.3 application.yml 配置参数3.4开启注册中心功能4.实战演练4.1 user-api 项目部分代码(服务提供)4.1.1添加依赖4.1.2配置参数4.1.3服务接口4.1.4开启服务注册功能4.2user-web 项目部分代码(服务消费)4.2.1添加依赖4.2.2配置参数4.2.3客户端4.2.4开启服务发现功能5.Eureka 集群5.1application.yml 文件需要进行如下修改:6.Eureka 与 Zookeeper 的区别6.1 CAP 理论6.2 Zookeeper 保证 CP6.3 Eureka 保证 AP7.源码地址1.前言Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。2.介绍Eureka 是 Netflix 的子模块,它是一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故障转移。服务注册和发现对于微服务架构而言,是非常重要的。有了服务发现和注册,只需要使用服务的标识符就可以访问到服务,而不需要修改服务调用的配置文件。该功能类似于 Dubbo 的注册中心,比如 Zookeeper。Eureka 采用了 CS 的设计架构。Eureka Server 作为服务注册功能的服务端,它是服务注册中心。而系统中其他微服务则使用 Eureka 的客户端连接到 Eureka Server 并维持心跳连接。其运行原理如下图:由图可知,Eureka 的运行原理和 Dubbo 大同小异, Eureka 包含两个组件: Eureka Server 和 Eureka Client。Eureka Server 提供服务的注册服务。各个服务节点启动后会在 Eureka Server 中注册服务,Eureka Server 中的服务注册表会存储所有可用的服务节点信息。Eureka Client 是一个 Java 客户端,用于简化 Eureka Server 的交互,客户端同时也具备一个内置的、使用轮询负载算法的负载均衡器。在应用启动后,向 Eureka Server 发送心跳(默认周期 30 秒)。如果 Eureka Server 在多个心跳周期内没有接收到某个节点的心跳,Eureka Server 会从服务注册表中将该服务节点信息移除。3.搭建注册中心3.1 创建Spring Boot项目3.2导入依赖(注意Spring Boot 与 SpringCloud 有版本兼容关系,如果引用版本不对应,项目启动会报错)<dependencies> <!-- eureka 服务端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> <version>2.1.0.RELEASE</version> </dependency></dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Dalston.SR1</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.9.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>3.3 application.yml 配置参数server: port: 9000 eureka: instance: hostname: localhost # eureka 实例名称 client: register-with-eureka: false # 不向注册中心注册自己 fetch-registry: false # 是否检索服务 service-url: defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ # 注册中心访问地址3.4开启注册中心功能在启动类上添加 @EnableEurekaServer 注解。@EnableEurekaServer@SpringBootApplicationpublic class EurekaServerApplication { public static void main(String[] args) { SpringApplication.run(EurekaServerApplication.class, args); } }启动项目,访问http://localhost:9000/ ,可看到 Eureka 服务监控界面,如下:4.实战演练了解 Eureka 的环境搭建后,我们需要进行实战直观的感受 Eureka 的真正作用,这样才能清楚掌握和学习 Eureka 。我们再创建两个 Spring Boot 项目,一个名为 user-api ,用于提供接口服务,另一个名为 user-web,用于调用 user-api 接口获取数据与浏览器交互。服务实例端口描述eureka9000注册中心(Eureka 服务端)user-api8081服务提供者(Eureka 客户端)user-web80服务消费者,与浏览器端交互(Eureka 客户端)4.1 user-api 项目部分代码(服务提供)4.1.1添加依赖同样主要版本问题 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- eureka 客户端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> <version>2.1.0.RELEASE</version> </dependency>4.1.2配置参数server: port: 8081 spring: application: name: user-api eureka: instance: instance-id: user-api-8081 prefer-ip-address: true # 访问路径可以显示 IP client: service-url: defaultZone: http://localhost:9000/eureka/ # 注册中心访问地址注意:http://localhost:9000/eureka/ 就是注册中心的地址。4.1.3服务接口public interface UserService { String getUserName(); }@Servicepublic class UserServiceImpl implements UserService { @Override public String getUserName() { return "张三"; } }@RestController@RequestMapping("/user")public class UserController { @Autowired private UserService userService; @RequestMapping("/getname") public String get() { return this.userService.getUserName(); } }注意:该 controller 是给 user-web 使用的(内部服务),不是给浏览器端调用的。4.1.4开启服务注册功能在启动类上添加 @EnableEurekaClient 注解。@EnableEurekaClient@SpringBootApplicationpublic class UserApiApplication { public static void main(String[] args) { SpringApplication.run(UserApiApplication.class, args); } }启动项目完成后,浏览器访问 http://localhost:9000 查看 Eureka 服务监控界面 ,如下图:从图可知,user 相关服务信息已经注册到 Eureka 服务中了。补充:在上图中,我们还看到一串红色的字体,那是因为 Eureka 启动了自我保护的机制。当 EurekaServer 在短时间内丢失过多客户端时(可能发生了网络故障),EurekaServer 将进入自我保护模式。进入该模式后,EurekaServer 会保护服务注册表中的信息不被删除。当网络故障恢复后,EurekaServer 会自动退出自我保护模式。4.2user-web 项目部分代码(服务消费)4.2.1添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- eureka 客户端 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> <version>2.1.0.RELEASE</version> </dependency>4.2.2配置参数server: port: 80 spring: application: name: user-web eureka: client: register-with-eureka: false # 不向注册中心注册自己 fetch-registry: true # 是否检索服务 service-url: defaultZone: http://localhost:9000/eureka/ # 注册中心访问地址4.2.3客户端@Configurationpublic class RestConfiguration { @Bean @LoadBalanced public RestTemplate getRestTemplate() { return new RestTemplate(); } }@RestController@RequestMapping("/user")public class UserController { @Autowired private RestTemplate restTemplate; @Resource private DiscoveryClient client; @RequestMapping("/getname") public User get() throws Exception { //getForObject() 发送一个HTTP GET请求,返回的请求体将映射为一个对象 //user-api 为调用的uri(服务提供者(Eureka 客户端)地址)在eureka上注册的application.name return restTemplate.getForObject( "http://user-api/user/getname",User.class); } }4.2.4开启服务发现功能在启动类上添加 @EnableDiscoveryClient 注解。@EnableDiscoveryClient@SpringBootApplicationpublic class UserWebApplication { public static void main(String[] args) { SpringApplication.run(UserWebApplication.class, args); } }启动项目后,使用浏览器访问 user-web 项目接口,运行结果如下:数据来源:user-api8081服务提供者(Eureka 客户端)5.Eureka 集群Eureka 作为注册中心,保存了系统服务的相关信息,如果注册中心挂掉,那么系统就瘫痪了。因此,对 Eureka 做集群实现高可用是必不可少的。本次测试使用一台机器部署 Eureka 集群,通过名字和端口区分不同的 eureka 服务。Eureka 名称端口号eureka019001eureka029002准备工作:由于我们使用了http://eureka01 这种写法,需要配一下host。给C:\Windows\System32\drivers\etc下面的hosts文件添加几个配置5.1application.yml 文件需要进行如下修改:server: port: 9001 spring: application: name: eureka-server profiles: active: eureka01 eureka: instance: hostname: eureka01 # eureka 实例名称 client: # register-with-eureka: false # 不向注册中心注册自己 # fetch-registry: false # 是否检索服务 service-url: defaultZone: http://eureka01:9001/eureka/,http://eureka02:9002/eureka/server: port: 9002 spring: application: name: eureka-server profiles: active: eureka02 eureka: instance: hostname: eureka02 # eureka 实例名称 client: # register-with-eureka: false # 不向注册中心注册自己 # fetch-registry: false # 是否检索服务 service-url: defaultZone: http://eureka01:9001/eureka/,http://eureka02:9002/eureka/两个 eureka 服务实例的配置文件修改方式类似,将名称和端口进行修改即可。服务注册的项目中,将 eureka.client.service-url.defaultZone 改成集群的 url 即可。启动一个服务时报错很正常,因为另外一个没有启动com.sun.jersey.api.client.ClientHandlerException: org.apache.http.conn.ConnectTimeoutException: Connect to eureka02:9002 timed out at com.sun.jersey.client.apache4.ApacheHttpClient4Handler.handle(ApacheHttpClient4Handler.java:187) ~[jersey-apache-client4-1.19.1.jar:1.19.1] at com.netflix.eureka.cluster.DynamicGZIPContentEncodingFilter.handle(DynamicGZIPContentEncodingFilter.java:48) ~[eureka-core-1.9.8.jar:1.9.8] at com.netflix.discovery.EurekaIdentityHeaderFilter.handle(EurekaIdentityHeaderFilter.java:27) ~[eureka-client-1.9.8.jar:1.9.8] at com.sun.jersey.api.client.Client.handle(Client.java:652) ~[jersey-client-1.19.1.jar:1.19.1] at com.sun.jersey.api.client.WebResource.handle(WebResource.java:682) ~[jersey-client-1.19.1.jar:1.19.1] at com.sun.jersey.api.client.WebResource.access$200(WebResource.java:74) ~[jersey-client-1.19.1.jar:1.19.1] at com.sun.jersey.api.client.WebResource$Builder.post(WebResource.java:570) ~[jersey-client-1.19.1.jar:1.19.1] at com.netflix.eureka.transport.JerseyReplicationClient.submitBatchUpdates(JerseyReplicationClient.java:116) ~[eureka-core-1.9.8.jar:1.9.8] at com.netflix.eureka.cluster.ReplicationTaskProcessor.process(ReplicationTaskProcessor.java:80) ~[eureka-core-1.9.8.jar:1.9.8] at com.netflix.eureka.util.batcher.TaskExecutors$BatchWorkerRunnable.run(TaskExecutors.java:193) [eureka-core-1.9.8.jar:1.9.8] at java.lang.Thread.run(Thread.java:748) [na:1.8.0_201] Caused by: org.apache.http.conn.ConnectTimeoutException: Connect to eureka02:9002 timed out at org.apache.http.conn.scheme.PlainSocketFactory.connectSocket(PlainSocketFactory.java:123) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.conn.DefaultClientConnectionOperator.openConnection(DefaultClientConnectionOperator.java:180) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.conn.AbstractPoolEntry.open(AbstractPoolEntry.java:144) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.conn.AbstractPooledConnAdapter.open(AbstractPooledConnAdapter.java:134) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.client.DefaultRequestDirector.tryConnect(DefaultRequestDirector.java:605) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.client.DefaultRequestDirector.execute(DefaultRequestDirector.java:440) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.client.AbstractHttpClient.doExecute(AbstractHttpClient.java:835) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:118) ~[httpclient-4.5.8.jar:4.5.8] at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:56) ~[httpclient-4.5.8.jar:4.5.8] at com.sun.jersey.client.apache4.ApacheHttpClient4Handler.handle(ApacheHttpClient4Handler.java:173) ~[jersey-apache-client4-1.19.1.jar:1.19.1] ... 10 common frames omitted效果如下:6.Eureka 与 Zookeeper 的区别两者都可以充当注册中心的角色,且可以集群实现高可用,相当于小型的分布式存储系统。6.1 CAP 理论CAP 分别为 consistency(强一致性)、availability(可用性) 和 partition toleranc(分区容错性)。理论核心:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求。因此,根据 CAP 原理将 NoSQL 数据库分成满足 CA 原则、满足 CP 原则和满足 AP 原则三大类: CA:单点集群,满足一致性,可用性的系统,通常在可扩展性上不高 CP: 满足一致性,分区容错性的系统,通常性能不是特别高 AP: 满足可用性,分区容错性的系统,通过对一致性要求较低 简单的说:CAP 理论描述在分布式存储系统中,最多只能满足两个需求。6.2 Zookeeper 保证 CP当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟前的注册信息,但不能接受服务直接挂掉不可用了。因此,服务注册中心对可用性的要求高于一致性。但是,zookeeper 会出现一种情况,当 master 节点因为网络故障与其他节点失去联系时,剩余节点会重新进行 leader 选举。问题在于,选举 leader 的时间较长,30 ~ 120 秒,且选举期间整个 zookeeper 集群是不可用的,这期间会导致注册服务瘫痪。在云部署的环境下,因网络问题导致 zookeeper 集群失去 master 节点的概率较大,虽然服务能最终恢复,但是漫长的选举时间导致注册服务长期不可用是不能容忍的。6.3 Eureka 保证 APEureka 在设计上优先保证了可用性。EurekaServer 各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和发现服务。而 Eureka 客户端在向某个 EurekaServer 注册或发现连接失败时,会自动切换到其他 EurekaServer 节点,只要有一台 EurekaServer 正常运行,就能保证注册服务可用,只不过查询到的信息可能不是最新的。除此之外,EurekaServer 还有一种自我保护机制,如果在 15 分钟内超过 85% 的节点都没有正常的心跳,那么 EurekaServer 将认为客户端与注册中心出现网络故障,此时会出现一下几种情况: EurekaServer 不再从注册列表中移除因为长时间没有收到心跳而应该过期的服务 EurekaServer 仍然能够接收新服务的注册和查询请求,但不会被同步到其他节点上 当网络稳定时,当前 EurekaServer 节点新的注册信息会同步到其他节点中 因此,Eureka 可以很好的应对因网络故障导致部分节点失去联系的情况,而不会向 Zookeeper 那样是整个注册服务瘫痪。7.源码地址源码下载以上为本人实际测试写下的,如有不足地方请指出。